

meta data de esta página
Vsphere Management Assistant
VMA (Vsphere Management Assistant )Es un appliance basado en Suse que nos va a permitir ejecutar comandos y scripts en varios ESX
Entramos al VMA por consola remota (ssh), con el usuario vi_admin
Una vez validados añadimos los servidores que vamos a gestionar con el comando
vifp addserver <host>
Una vez añadidos podemos sacar un listado con
vifp listservers
Para conectarnos a un esx determinado de la lista , lo hacemos con el comando
vifptarget -s <host>
Una vez conectados podemos ejecutar multitud de comandos, veamos algunos de los más comunes:
- Estadísticas de rendimiento
resxtop
- Listador de tarjetas de red del servidor
vicfg-nics -l
- Ejecutar comandos en el Servidor
vicfg-hostops --operation reboot/shutdown
- Entrar en modo mantenimiento
vicfg-hostops --operation enter - Backup/restore del servidor
vicfg-cfgbackup
- Conectarnos al vcenter
vicfg-hostops -server vcenter -username xxxxxxxx -password
- Ejecutar comandos en las máquinas virtuales
vmware-cmd --help
- Listar las máquinas virtuales
vmware-cmd -l
- Registrar una MV
vmware-cmd -s register /vmfs/volumenes/datastore/vms/mv.vmx
- Hacer snapshot
vmware-cmd /vmfs/volumenes/datastore/vms/mv.vmx createsnapshot <nombre> "descripción" 0|1 0|1
Tambien podemos ejecutar scripts. De hecho en /opt/vmware/vma/samples/perl tenemos el script mcli.pl que nos permite ejecutar el mismo comando en múltiples servidores ESX.
./mcli.pl servidores comando
donde servidores es un archivo creado por nosotros donde ponemos una línea por cada servidor al que nos vamos a conectar y comando es el comando a ejecutar. Por ejemplo para listar las tarjtas de red de un grupo de servidores
./mcli.pl servidores vicfg-nics -l
resxtop
El comando resxtop es lo mismo que el comando esxtop del propio servidor ESX cuando accedemos localmente a un equipo. Este comando nos permite sacar estadísticas a tiempo reali a fin de solucionar problemas o cuellos de botella
El resxtop tiene tres modos de funcionamiento
- modo interactivo →desde la consola del vma
- modo batch
resxtop -a -b >estadisticas.csv
- modo replay recolecciona los datos usando vm-suppor
Ejecutamos el comando resxtop y aparecerá una ventana similar a esta

Una vez en dicha consola podemos cambiar de vista según la tecla que pulsemos:
- m → Memoria
- c →CPU
- n →Red
- d →adaptador de disco
- u →Dispositivo de almacenamiento
- v →Disco por VM
- i →Interrupciones
- p →consumo de potencia
- h →ayuda
además dentro de cada vista podemos presionar distintas teclas
- f →para añadir o quitar colummnas
- V →para ver sólo las instancias de MVs
- 2 →para ir resaltando una línea hacia abajo(presionando varias veces cambia sucesivamente de línea)
- 8 →para ir resaltando una línea hacia arriba(presionando varias veces cambia sucesivamente de línea)
- barraespacio →refresca la pantalla
- s 5→refresca la pantalla cada 5 segundos
Detectar cuellos de botella
Problemas en la red
ejecutamos resxtop →n
Presionamos f y elegimos las columnas A B C D E F K L y comprobamos las columnas %DRPTX y %DRPRX que corresponden con los Dropped Packages trasnmitted y received.
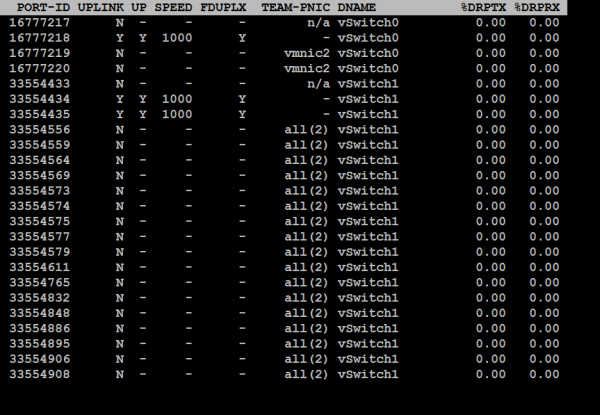
Si en el número de paquetes recibidos rechazados %DRPRX >0 indica problemas de rendimiento en la red. La solución sería aumentar los recursos CPU de la MV o incrementar la eficiencia de la MV cambiando el driver.
Si %DRPTX>0 las posibles soluciones serian:
- añadir otro uplink al virtual switch
- mover las MV con alta E/S a diferente switch
- reducir el tráfico de red de la MV
Problemas de Almacenamiento
resxtop → d presionamos f y elegimos las columnas A B G J
Los parámetros a mirar son :
- DAVG Latencia a nivel de disco . Si es >25 indica problemas de rendimiento, debidos normalmente a que no está usando la cache
- ABRTS/s Comandos abortados por sg.Si es >1 es que el almacenamiento no ha respondido
- KAVG Latencia causada por el VMKernel. Si es >3 indica problemas con las colas →revisar en el host ESXi el tamaño de la cola o la política de failover
- GAVG es la suma de DAVG y KAVG. si es >25 problemas
- Resets. indica el número de comandos reseteados por sg. Si es >1
Otros parámetros para medir el rendimiento
- READs/s y WRITES/s. La suma de ambos es igual a IOPS
- CMDS/s=IOPS en esxtop
- ACTV →comandos activos
- QUED→comandos encolados →indica problemas de latencia
- ABRTS→ Comandos abortados →indica problemas. Si estamos mirando una LUN determinada y ABRTS>0 el almacenamiento está sobrecargado en dicha LUN
También podemos mirar el rendimiento desde el esxtop y luego UFJ http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=1008205
VSCSISTATS
vscsistats es otra herramienta para medir el rendimiento del almacenamiento en las MV.
Con Vscsistats podemos ver lo siguiente de una máquina virtual:
- ioLength
- seekDistance
- outstandingIOs
- latency
- interarrival
Para listar las mv que tenemos en el ESX ejecutamos
/usr/lib/vmware/bin/vscsiStats -l
Con este comando obtenemos el worldGroupID de la máquina/s virtuale/es.
Si queremos obtener las estadísticas de una MV en concreto ejecutamos
vscsistats -s -w <uid de la mv>
Si sólo nos interesa un disco en particula de dicha MV
vscsistats -s -w worldGroupID -i handleID
Mientras dura la recolección podemos ejecutar vscsistats con -p para obtener información de all, ioLength, seekDistance, outstandingIOs, latency, interarrival.
Por ejemplo si queremos ver la latecia
vscsistats -p latency
paramos la recolección con
vscsistats -x